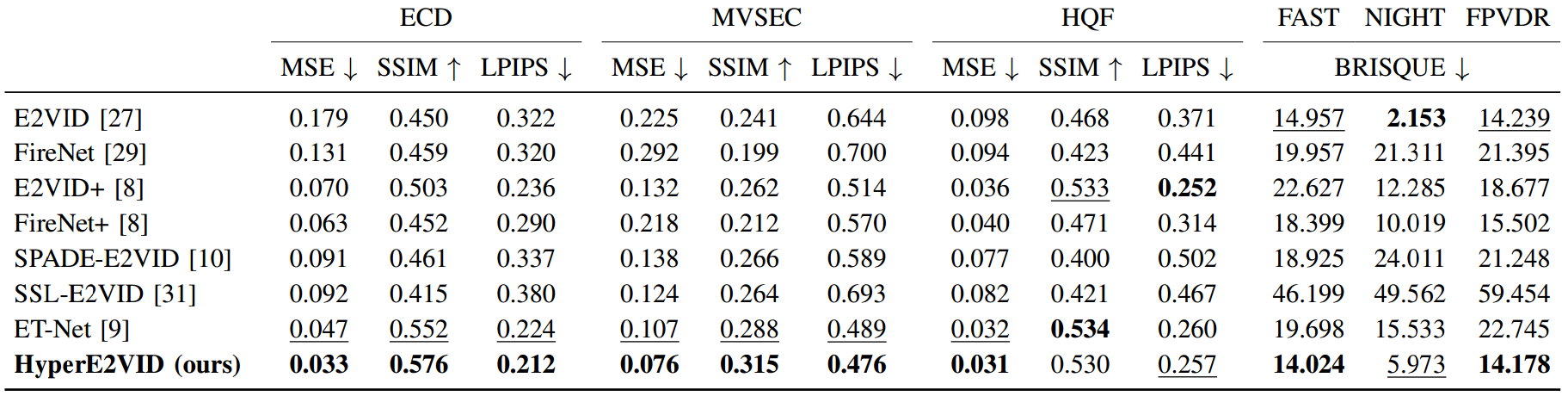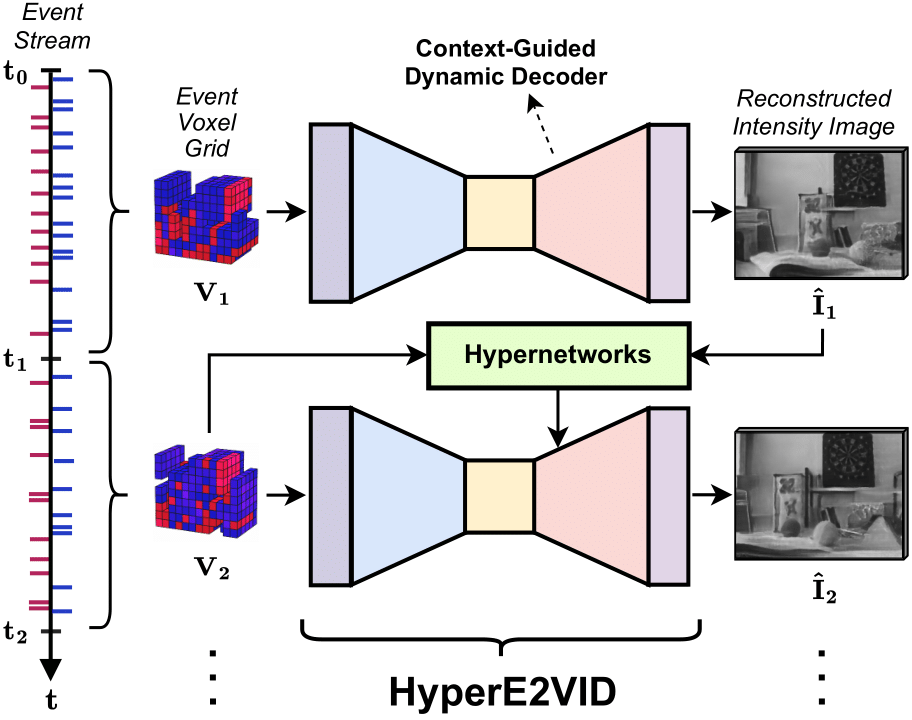
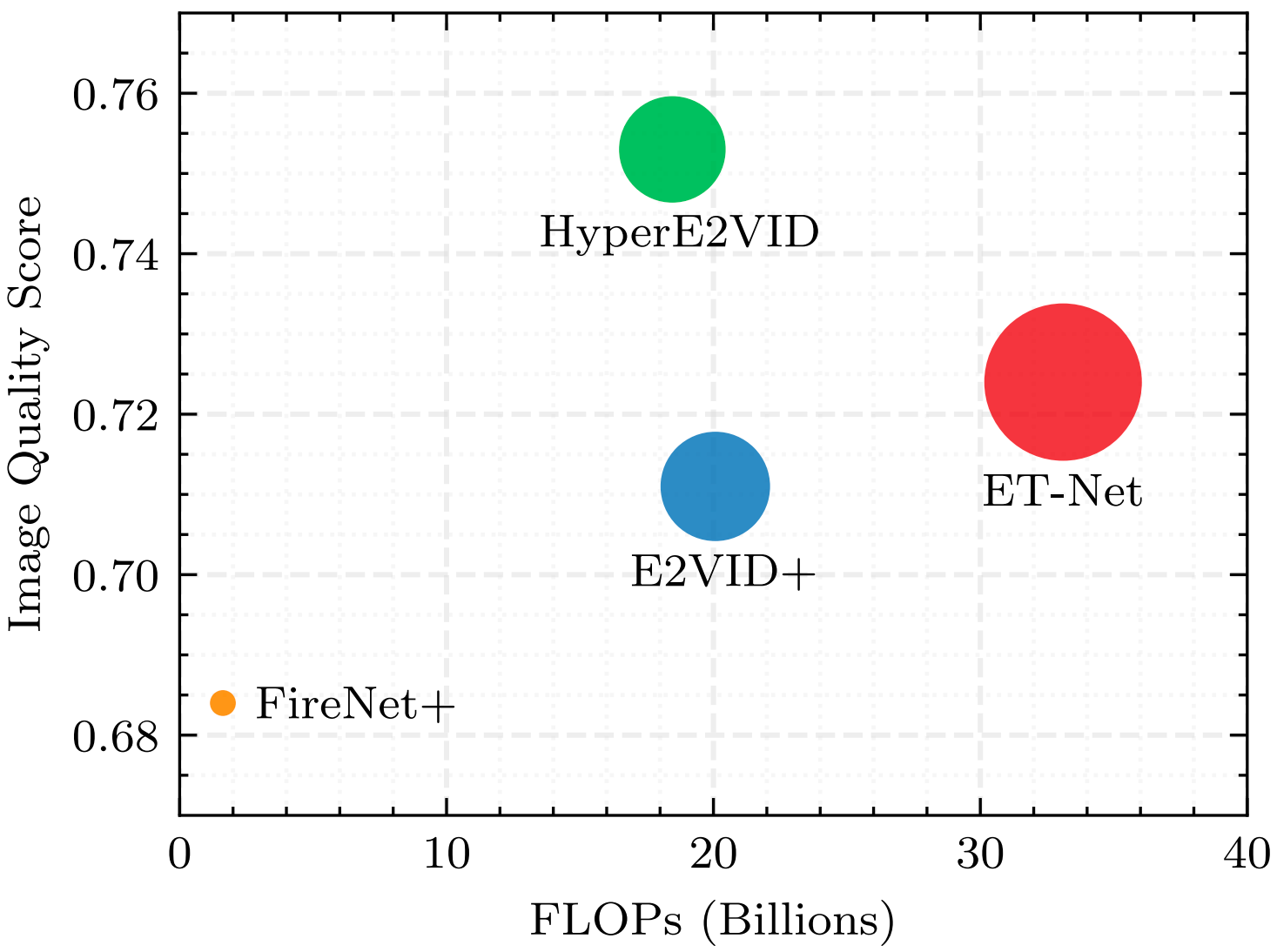
Since events are generated asynchronously only when the intensity of a pixel changes, the resulting event voxel grid is a sparse tensor, incorporating information only from the changing parts of the scene. The sparsity of these voxel grids is also highly varying. This makes it hard for neural networks to adapt to new data and leads to unsatisfactory video reconstructions that contain blur, low contrast, or smearing artifacts. Unlike the previous methods that try to process the highly varying event data with static networks in which the network parameters are kept fixed after training, our proposed model, HyperE2VID, employs a dynamic neural network architecture . Specifically, we enhance the main network (a convolutional encoder-decoder architecture similar to E2VID) by employing dynamic convolutions, whose parameters are generated via hypernetworks, dynamically at inference time.
Some important aspects of our approach are:
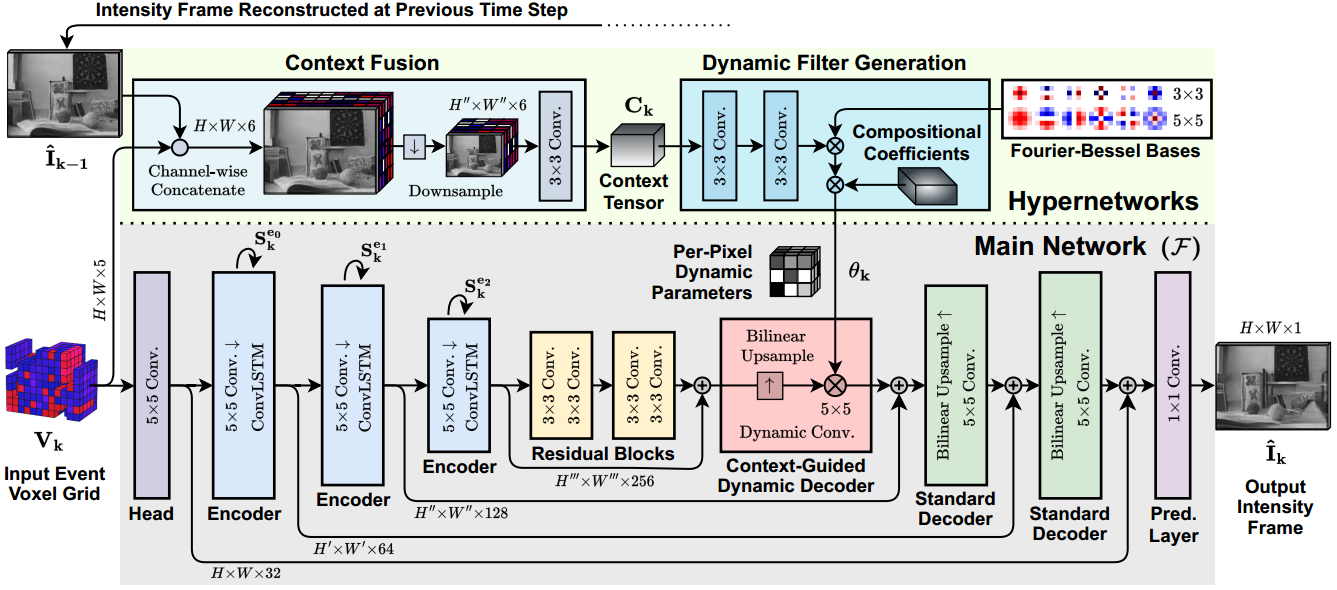
- The dynamically generated parameters are also spatially varying such that there exists a separate convolutional kernel for each pixel, allowing them to adapt to different spatial locations as well as each input. This spatial adaptation enables the network to learn and use different filters for static and dynamic parts of the scene where events are generated at low and high rates, respectively.
- To avoid the high computational cost of generating per-pixel adaptive filters, we use two filter decomposition steps while generating per-pixel dynamic filters. First, we decompose filters into per-pixel filter atoms generated dynamically. Second, we further decompose each filter atom into pre-fixed multi-scale Fourier-Bessel bases.
- We guide the dynamic filter generation through a context that represents the current scene being observed. This context is obtained by fusing events and previously reconstructed images. These two modalities complement each other since intensity images capture static parts of the scene better, while events excel at dynamic parts. By fusing them, we obtain a context tensor that better represents both static and dynamic parts of the scene.
- We also employ a curriculum learning strategy to train the network more robustly, particularly in the early epochs of training when the reconstructed intensity images are far from optimal.
For more details please see our paper.